Dynatrace's official price list shows that Full-Stack Monitoring is around US$58 per month per 8 GiB host, which, combined with infrastructure monitoring, security modules and actual host counts, can easily add up to hundreds of thousands or even more than a million dollars per year in medium to large environments. level. For a Hong Kong bank running hundreds to thousands of VMs, Kubernetes nodes, containers, and multi-region environments, it's no exaggeration that the APM/observability bill has jumped to the "top 5 IT expenses".
At the same time, the HKMA has re-emphasized its "risk-based, technology-neutral" supervisory approach in its latest revision of TM-E-1: it does not prescribe which instrument to use, but rather requires banks to implement risk management controls that are commensurate with the risk and "fit for purpose" and to assess their effectiveness through ongoing inspections and off-site reviews. Rather, it requires banks to implement risk management controls that are commensurate with risk and "fit for purpose", and to assess their effectiveness through ongoing examinations and off-site reviews. In other words, in the eyes of the regulator, the focus is never on "did you use Dynatrace", but rather on "can you demonstrate that critical services are properly monitored and that exceptions are detected and addressed in a timely manner".
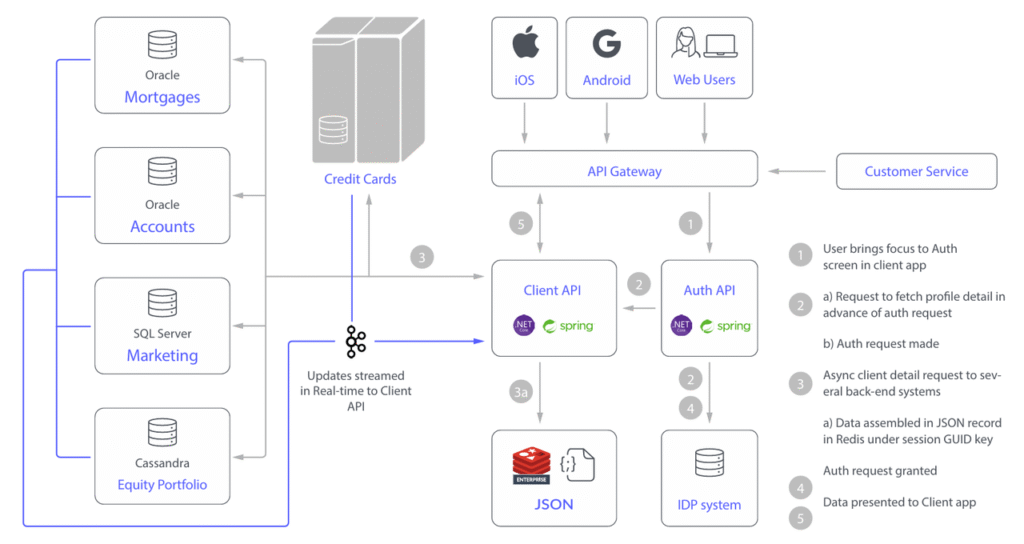
For CISOs, cost-sensitive CIOs and CFOs, this opens up a very real question: in the "Dynatrace alternatives Hong Kong" option, is there a way to use an open stack such as Redis + Grafana to make a new product in 2 years? Real-time monitoring cost comparison Overwhelming Advantage on - without Regulatory Challenge?