In the research and development of autonomous driving perception systems, the performance of AI models is highly dependent on large-scale, high-quality perception datasets. Currently, widely adopted open-source datasets in the industry include KITTI, nuScenes, and the Waymo Open Dataset, among others; these datasets have laid a critical foundation for the evolution of autonomous driving algorithms.
However, building real-world on-site perception datasets is no easy task—companies not only need to invest significant human, material, and time resources, but must also contend with numerous severe challenges, including data collection constraints, privacy compliance, time-consuming data annotation, and the difficulty of capturing extreme/ rare scenarios.
Against this backdrop, high-fidelity virtual datasets are rapidly emerging as a new frontier in the research of perception algorithms for autonomous driving. Through virtual data generated by simulation platforms, R&D teams can not only rapidly scale up the volume of data but also flexibly simulate complex road conditions, adverse weather, and rare unexpected events, thereby providing perception models with more comprehensive and diverse training samples.
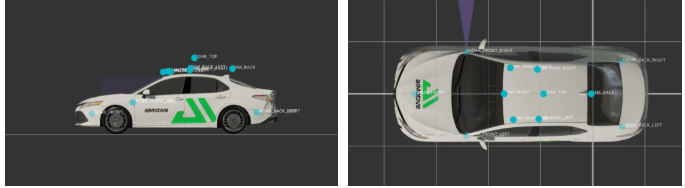
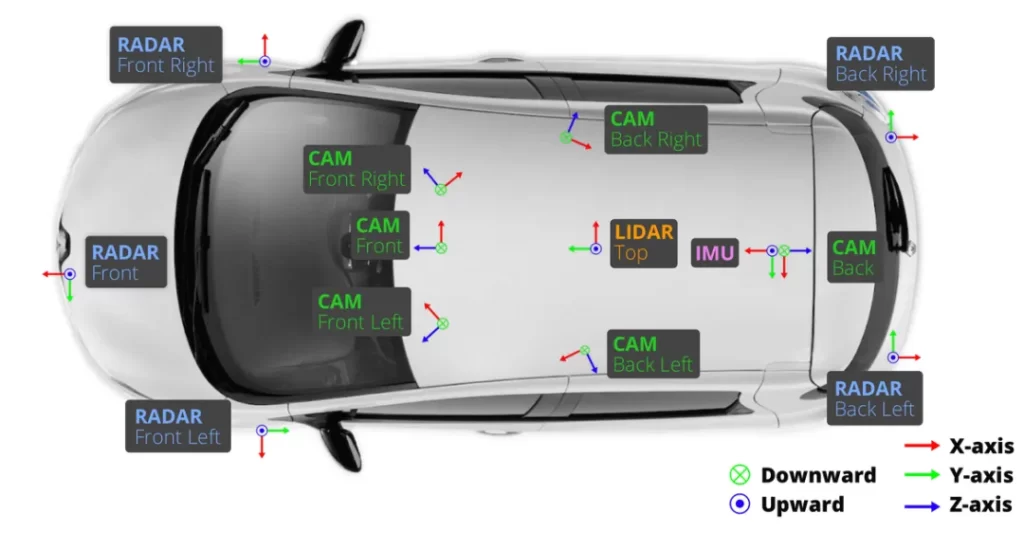
Based on this,HOSCOWe have launched a brand-new high-fidelity virtual dataset—SimData. SimData Deep Trust aiSim simulation platformWith its high-precision physical modeling and realistic visual rendering capabilities, it can efficiently generate synchronized data from multiple sensors (including cameras, LiDAR, millimeter-wave radar, IMUs, and more), perfectly achieving multimodal characteristics that closely align with real-world data.
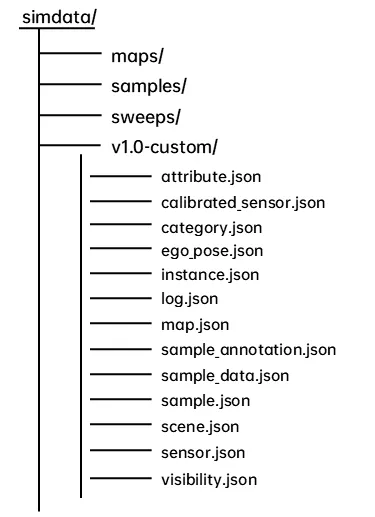
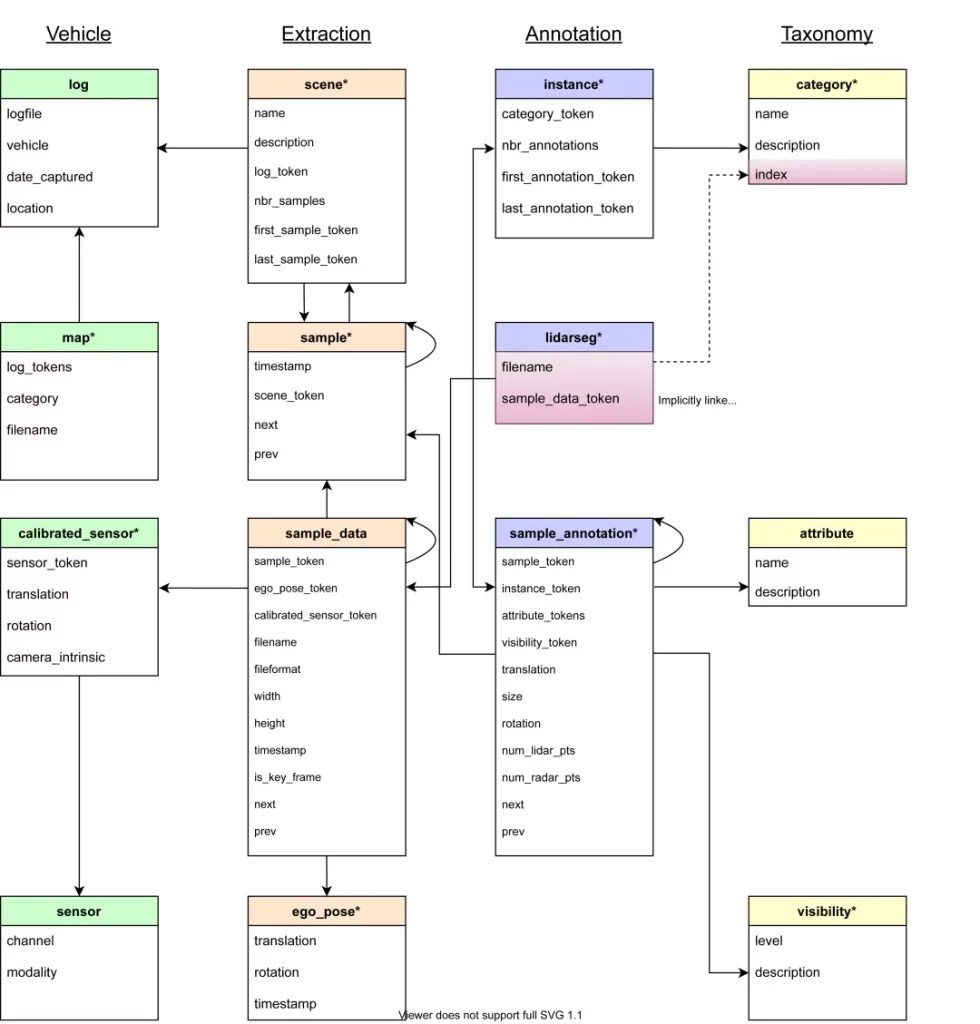
SimData's data structure strictly follows nuScenes Data Set Format Specification, developers can directly use the official nuscenes-devkit The tool performs data analysis and visualization, significantly reducing the time and effort required for R&D personnel to adapt to and master it.
This article will provide an in-depth analysis of SimData’s core features and development process, and comprehensively demonstrate its actual performance in typical autonomous driving perception tasks.SimData Official ReleaseThe report and related comparison test results will be released shortly, so please stay tuned.HOSCOThe latest updates and technical insights.