虹科動態
【虹科方案】從被動防禦到主動預防:用 KnowBe4 輕鬆應對年度風險評估與安全審核
香港《保護關鍵基礎設施(電腦系統)條例》規定企業須每年執行資安風險評估、每兩年完成獨立審核,多數企業僅側重技術漏洞,卻忽略佔八成網安事故的人為風險。KnowBe4 透過模擬釣魚測試量化員工風險,建立動態風險評分機制,完整留存測試、培訓改善數據,一鍵匯出監管級報告,協助企業落實持續風險管理,輕鬆應對年度評估與安全審核

Lorem ipsum dolor sit amet, consectetur adipiscing elit.Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
在自動駕駛感知系統(Autonomous Driving Perception Systems)的研發進程中,AI 模型的性能表現極度依賴大規模且高質量的感知數據集(Perception Datasets)。現時業界廣泛採用的開源數據集包括 KITTI、nuScenes、Waymo Open Dataset 等,這些數據為自主駕駛算法的演進奠定了關鍵基石。
然而,構建真實世界的實地感知數據集絕非易事——企業不僅需要投入龐大的人力、物力與時間成本,更必須面對數據採集受限、隱私法規合規性(Privacy Compliance)、數據標註耗時,以及極端/罕見場景(Edge Cases)難以捕捉等諸多嚴峻挑戰。
在此背景下,高保真虛擬數據集(High-Fidelity Virtual Datasets)正迅速成為自動駕駛感知算法研究的全新方向。透過仿真平台(Simulation Platforms)所生成的虛擬數據,研發團隊不僅能快速擴展數據規模,更可靈活模擬複雜路況、惡劣天氣及罕見突發事件,從而為感知模型提供更全面且具備多樣性的訓練樣本。
基於此,虹科推出了全新的高保真虛擬數據集——SimData。SimData 深度依託 aiSim 仿真平台的高精度物理建模與逼真視覺渲染能力,能夠高效生成多傳感器同步數據(包括相機/攝像頭、激光雷達 LiDAR、毫米波雷達 Radar、IMU 慣性測量單元等),完美實現與真實世界數據高度一致的多模態(Multimodal)特性。
SimData 的數據結構嚴格遵循 nuScenes 數據集格式規範,開發者可直接利用官方提供的 nuscenes-devkit 工具進行數據解析與可視化呈現,大幅降低研發人員的適配與上手成本。
本文將深入剖析 SimData 的核心特性與構建流程,並全面展示其在典型自動駕駛感知任務中的實際表現。SimData 正式版及相關對比測試報告將於近期隆重發佈,敬請持續關注虹科的最新動態與技術分享。
在 aiSim 仿真平台中,我們嚴格復現了 nuScenes 數據集的傳感器配置與佈局,以確保數據結構與多模態同步特性(Multimodal Synchronization)的高度一致。
仿真車輛共配置了 6 路環視相機(Surround Cameras)、5 個毫米波雷達(Radar)、1 個激光雷達(LiDAR)、1 個慣性測量單元(IMU)以及 1 個全球定位系統(GPS)。其中,相機與雷達的採樣頻率均設定為 40 Hz,而激光雷達的採樣頻率高達 80 Hz,完美滿足了高時序精度(High Temporal Precision)的多傳感器同步數據採集需求。
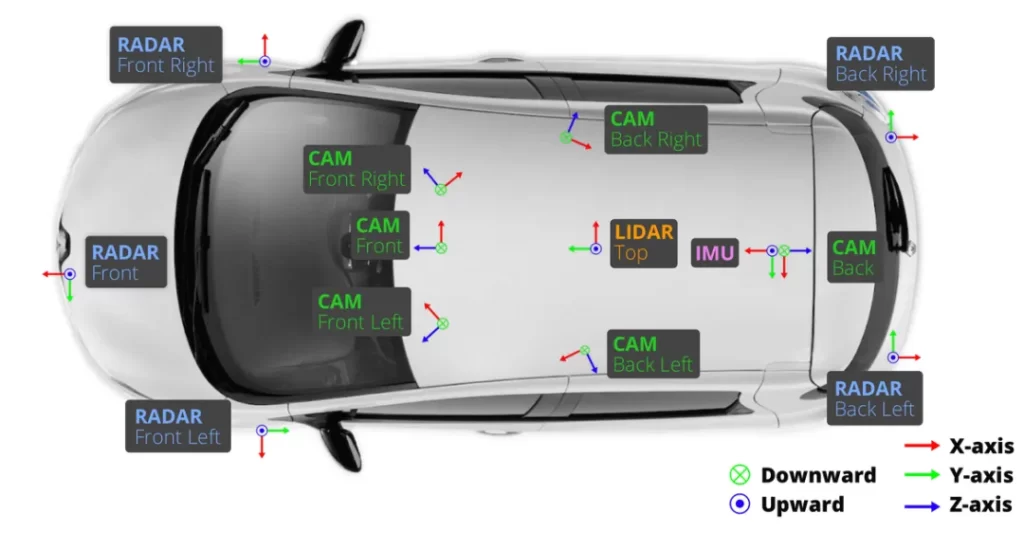
各傳感器的空間佈設、位置與朝向如下圖所示:

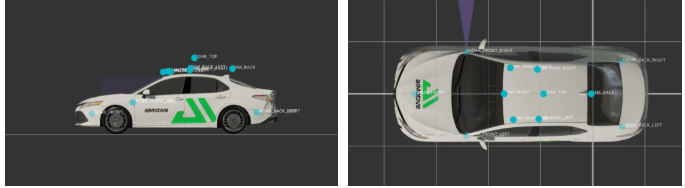
與 nuScenes 數據集有所不同的是,SimData 中所有傳感器均採用統一的 FLU(Forward–Left–Up)坐標系;而在原生 nuScenes 數據集中,相機傳感器則使用 RDF(Right–Down–Forward)坐標系。
在數據集構建過程中,我們已對所有標註文件(Annotation Files)進行了極其嚴格的坐標系轉換與對齊優化,確保坐標定義在邏輯層面上與 nuScenes 完全一致。因此,用戶在部署與使用 SimData 時,無需額外花費精力處理坐標差異,其數據解析與二次開發體驗與原生 nuScenes 保持無縫一致。下圖展示了 nuScenes 中各傳感器的典型佈局及其坐標系定義。
SimData 數據集在結構設計與目錄規劃上與 nuScenes 完全保持一致。對於已經熟悉 nuScenes 框架的算法工程師與開發者而言,無需任何額外的適配、轉換或學習成本,即可快速上手 SimData 的部署、使用與解析。
下圖具體展示了 SimData 數據集的整體目錄結構,nuScenes 亦同樣遵循此組織形式,旨在實現無縫兼容與工具級的互通互用(Tool-level Interoperability)。
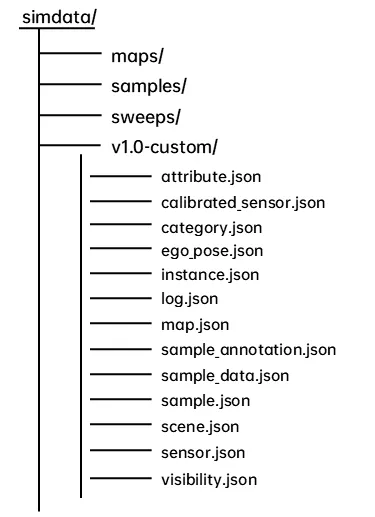
具體核心目錄與文件架構說明如下:
maps 文件夾 存放數據集中所涉及的所有高精地圖(HD Maps)圖像文件,主要用於提供精確的地理位置信息(Geospatial Information)與場景背景參考。
samples 文件夾 存放各類傳感器的關鍵幀(Keyframes)數據,具體包括:
6 路攝像頭/相機圖像(.jpg 格式)
5 路毫米波雷達點雲(.pcd 格式)
1 路激光雷達 LiDAR 點雲(.bin 格式) 其中,系統每隔 0.5 秒抽取一幀數據作為關鍵幀進行精準保存。
sweeps 文件夾 保存除關鍵幀以外的連續傳感器數據(Continuous Sensor Data),主要用於構建時序信息(Temporal Information)以及執行多幀融合(Multi-frame Fusion)等高級感知任務。
v1.0-* 文件夾 存放傳感器的標註信息(Annotations)與元數據(Metadata)。所有文件均以 .json 格式保存,涵蓋了時間戳(Timestamps)、自車姿態參數(Ego-pose)、標註標籤(Labels)、場景描述(Scene Descriptions)等核心內容。
各個 .json 標註文件之間的關係網絡亦與 nuScenes 數據集保持完美一致,此處以 nuScenes 官方的文件結構圖進行詳細說明:
在 SimData 數據集中,每個數據文件中的信息塊均透過一個全球唯一的 UUID(Universally Unique Identifier) 作為 Token 進行唯一標識。這些 Token 構成了數據集中不同數據維度之間的關聯橋樑。用戶只需透過 sample.json、sample_data.json 和 sample_annotation.json 三個核心文件,即可高效獲取絕大多數的標註數據與結構化信息(Structured Information)。
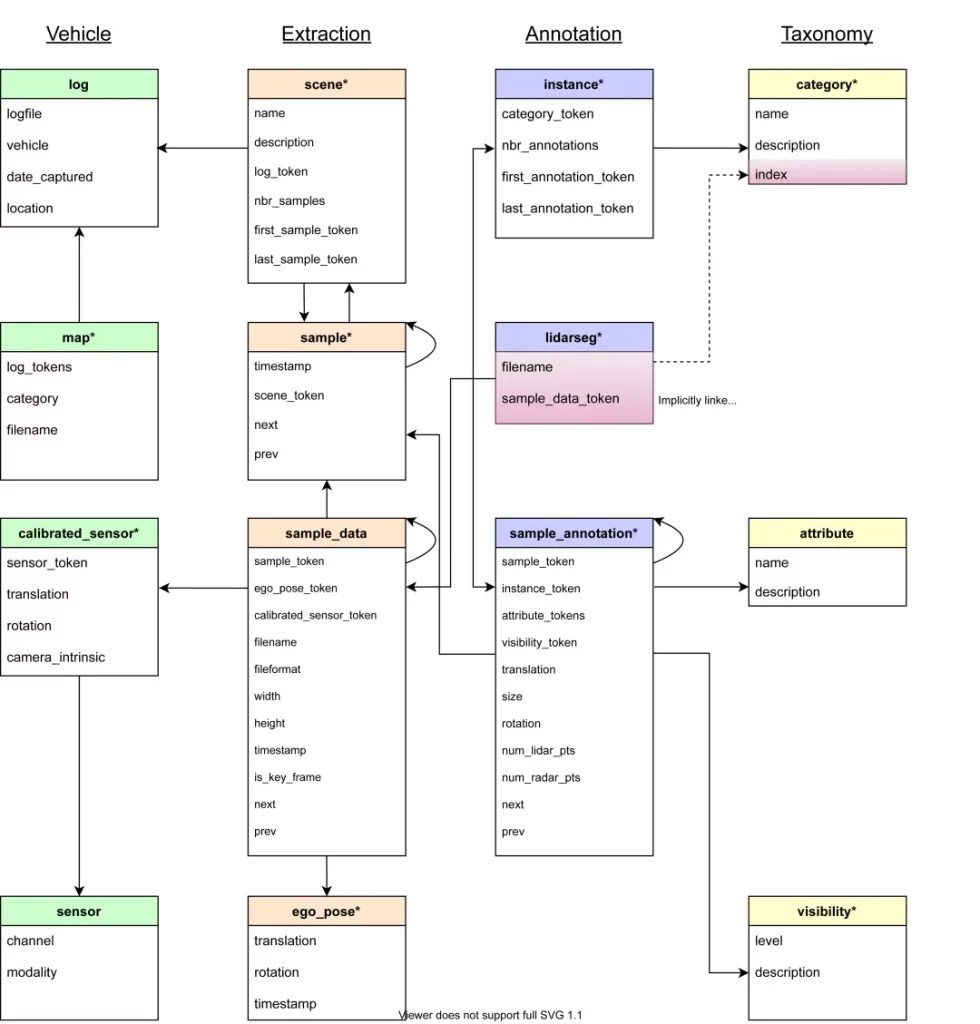
sample.json 文件詳細記錄了關鍵幀(Keyframe)的基礎核心信息。
每個關鍵幀均對應一個唯一的 sample_token,用於精確標識該幀數據。
開發者透過 scene_token 即可在 scene.json 文件中快速檢索到該樣本所隸屬的具體仿真場景。
文件內還提供了前一幀(prev)與後一幀(next)的 Token 指針,可用於構建連續的時序影格/幀關係(Continuous Frame Relations)。
利用 sample_token,開發者可在 sample_data.json 中全面獲取對應幀的多傳感器數據詳情,具體包括:
ego_pose_token:車輛自車位姿(Ego-pose)的引用,可在 ego_pose.json 中獲得該特定時刻的精確位姿信息(包括三維位置與朝向)。
calibrated_sensor_token:對應傳感器的標定參數(Calibration Parameters),可在 calibrated_sensor.json 中查詢到該傳感器的精準內參(Intrinsic)與外參(Extrinsic)信息。
filename:傳感器原始數據(Raw Data)的文件路徑。若該數據屬於相機,則還會額外包含圖像的高度(height)與寬度(width)。
timestamp:時間戳(單位:微秒),用於多傳感器之間的時間硬同步(Time Synchronization)。
is_key_frame:布爾值(Boolean),用以指示該特定影格是否為關鍵幀。
next / prev:分別指向下一幀和前一幀的 Token,從而實現精準的時序關聯(Temporal Association)。
sample_annotation.json 文件精確記錄了每個關鍵幀中檢測到的目標物體 3D 標註信息(Object Annotations),可完全透過 sample_token 進行跨表關聯。其包含的主要核心字段如下:
instance_token:目標實例(Object Instance)的唯一標識。 開發者可在 instance.json 中查詢到該實例對應的 category_token(類別信息)、以及該物體首次與最後出現的關鍵幀 Token。透過 category_token 則可進一步在 category.json 中獲取該實例的具體語意類別名稱(Category Name)。
visibility_token: 可見度等級標識(共分為四個級別,數值越大代表物體可見度越高),其具體定義可在 visibility.json 中進行查閱。
目標物體的幾何與姿態信息(Geometry and Pose),這些位姿數據均精確定義在傳感器坐標系下:
中心點位置 (translation)
尺寸大小 (size)
旋轉角度 (rotation),以四元數(Quaternion)形式進行存儲。
點雲統計信息(Point Cloud Statistics): 檢測框(Bounding Box)內所包含的激光雷達點數(num_lidar_pts)與毫米波雷達點數(num_radar_pts)。
前後幀關聯(Frame Association): 分別精確記錄該目標實例在前一幀與後一幀中所對應的 Token 標識。
SimData 支持直接使用 nuScenes-devkit 進行數據解析,其實際調用與使用方法與原生 nuScenes 數據集完全一致。代碼調用示例如下:
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version=’v1.0-custom’, dataroot=data_path, verbose=True)
成功獲取實例化對象(Instantiated Object)後,研發人員便可直接調用 nuScenes 官方提供的完整工具鏈,對 SimData 數據集進行深度分析與感知模型訓練。配合 cv2 或 matplotlib 等可視化庫,即可直觀地對數據集進行 3D 可視化呈現:
具備 Ground Truth (GT) 真值框的 6 路相機/攝像頭圖像輸出:
同步的 LiDAR 激光雷達點雲數據,可同步繪製出 BEV(Bird’s Eye View,鳥瞰圖)視角下的精確標註信息:

以下是直接使用在原生 nuScenes 數據集下訓練完成的預訓練權重(Weights),採用 BEVFormer-tiny 模型在未進行任何 SimData 增量訓練或微調(Zero-shot Inference)的情況下,直接進行目標檢測的實際效果展示:
BEVFormer 官方代碼庫:https://github.com/fundamentalvision/BEVFormer/tree/master
BEVFormer 權威學術論文:https://arxiv.org/pdf/2203.17270
本文深入闡述了虛擬數據集在自動駕駛感知演算法研究與實用化落地中的核心重要性,並全面介紹了基於 aiSim 高精度仿真平台所生成的全新高保真虛擬感知數據集——SimData。
文章詳細說明了 SimData 的數據組成結構、底層 Schema 與具體解析方法,並透過主流開源感知模型(如 BEVFormer)對其進行了跨數據集的檢測驗證,從而有力地證明了該虛擬數據集在實際研發環境中的高度可用性與技術有效性。
後續,虹科團隊(Hongke Team)將陸續發佈更為詳盡的數據測試與指標對比報告,以進一步量化驗證 SimData 與真實世界數據集之間的核心高一致性(High Domain Consistency)。透過這一系列的技術深耕,我們不僅實證了 aiSim 仿真環境的極致高保真特性,更為全球的科研人員與自動駕駛開發者提供了一個高質量、即插即用且具備極佳擴展性的虛擬感知數據資源,持續為自動駕駛感知算法的研究、迭代與模型訓練提供強大助力。
敬請密切關注虹科後續關於正式版虛擬數據集的重磅發佈!若您希望深入了解更多關於自動駕駛仿真與虛擬數據集的應用方案,歡迎與我們取得聯繫。
香港《保護關鍵基礎設施(電腦系統)條例》規定企業須每年執行資安風險評估、每兩年完成獨立審核,多數企業僅側重技術漏洞,卻忽略佔八成網安事故的人為風險。KnowBe4 透過模擬釣魚測試量化員工風險,建立動態風險評分機制,完整留存測試、培訓改善數據,一鍵匯出監管級報告,協助企業落實持續風險管理,輕鬆應對年度評估與安全審核
眾多規則密集型企業於數位轉型時,常面臨業務規則與底層程式綁死、調校流程繁瑣、跨系統邏輯難統一等痛點。低程式碼可將判斷邏輯轉為可視化配置,縮短規則迭代週期,釐清業務與IT分工。Decisions平台整合低程式碼環境與規則引擎,獨立搭建共用決策層,支援拖拉式規則管理、跨系統串接調用,兼顧營運彈性與IT治理監管需求。
深入了解虹科 Panorama Suite 如何利用標準 REST Web Service (REST API) 實現雙向數據交換,打破工業現場數據孤島,將 SCADA 系統完美連接真實世界的天氣、能源與遙測大數據,全面加速企業 IT 與 OT 的深度融合。
