虹科動態
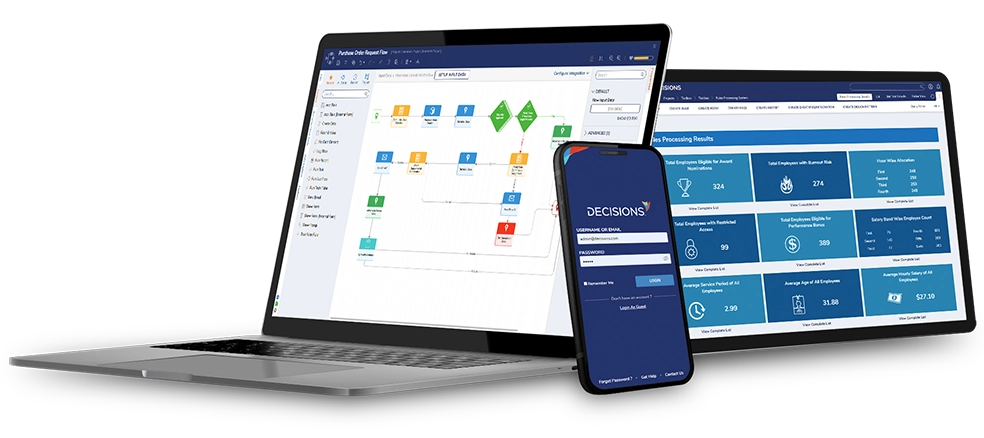
【虹科動態】為何規則密集型業務更適合低程式碼:把決策邏輯從「寫死」變「可配置」
眾多規則密集型企業於數位轉型時,常面臨業務規則與底層程式綁死、調校流程繁瑣、跨系統邏輯難統一等痛點。低程式碼可將判斷邏輯轉為可視化配置,縮短規則迭代週期,釐清業務與IT分工。Decisions平台整合低程式碼環境與規則引擎,獨立搭建共用決策層,支援拖拉式規則管理、跨系統串接調用,兼顧營運彈性與IT治理監管需求。

Lorem ipsum dolor sit amet, consectetur adipiscing elit.Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
多模型數據庫(Multi-model Database)之所以出現,核心背景往往不是「數據庫種類不夠」,而是業務系統的複雜度持續攀升,讓單一模型很難同時滿足「屬性查詢」與「關係遍歷」的混合需求。當「關聯式數據庫(Relational DB)+ 圖數據庫(Graph DB)」被放進同一條業務鏈路、一起承載關聯型業務邏輯時,系統架構複雜度常會以非線性的速度上升,且上升幅度往往超出設計初期的預期。

常見的架構演進路徑是:原本的關聯式數據庫繼續存放實體數據與核心欄位;新增圖數據庫專門存放實體間的關係,主攻多跳查詢(Multi-hop Traversal);然後由應用層(Application Layer)負責把兩邊的結果「黏」回同一個回傳物件。設計文件上看起來邊界清楚:關聯式回答「數據是什麼」、圖數據庫回答「數據怎麼連」,但真實世界的查詢需求幾乎不會乖乖待在單一模型裡。
實務上,多數查詢都是「屬性 + 關係」的混合型態:先撈取「近 30 天活躍用戶」(屬性過濾,偏向關聯式),再看這批人之間的好友/互動關係(多跳遍歷,偏向圖數據庫);或先找出「高風險帳戶」(屬性與交易紀錄過濾),再沿著關聯路徑往外擴散排查潛在關係人。這些在業務語意上其實是一個閉環,但在「關聯式 + 圖數據庫」混用的架構下,會被迫拆成多段流程:先在關聯式數據庫過濾出 ID 清單、再同步或即時推送到圖數據庫、在圖裡面做遍歷、最後回到應用層進行二次拼裝與加工。真正吞噬企業開發成本的,往往是「跨系統拼接查詢語意」,而不是某一個數據庫本身。
接著,技術團隊會遇到更棘手的數據一致性(Data Consistency)問題:
為了補救這些架構漏洞,團隊通常會加上事件驅動架構(Event-driven Architecture)/訊息隊列(Message Queue)、補償機制、定期檢核與修復任務,並在業務層接受某種程度的最終一致性(Eventual Consistency);但這些「補強」措施會逐步把系統重心從創造業務價值,轉移到容錯與糾錯之上。
更容易被忽略、但殺傷力極強的是交易/事務(Transaction)語意被拆碎:原本在單一數據庫中,一個業務操作可以包在同一個 ACID 交易裡,失敗就完整回滾(Rollback);混用之後,一次業務操作變成多次跨系統寫入,強一致性(Strong Consistency)常退化成最終一致性,回滾邏輯也被迫上移到應用層手動編寫。結果就是:狀態判斷充斥在核心流程中、錯誤處理「入侵」業務程式碼、系統行為變得越來越難以推理。排查一個問題需要跨兩套數據庫與整條呼叫鏈,定位成本大幅飆升。
當複雜度累積到某個臨界點,架構反而會限制業務的演進速度:一個微小的需求可能同時需要修改關聯式數據庫、圖數據庫、同步管道(Pipelines)與應用層拼裝;一個小異常可能要跨多個技術棧(數據庫、隊列、服務)追查數天。團隊的技術決策變得越來越保守,因為任何改動都可能踩爆既有的跨系統耦合點。這時,企業即便擁有了很強的圖查詢能力,也常常被「整合與一致性成本」徹底吞沒。
所以問題不在「圖數據庫」本身,而在於「分裂的數據視圖(Split Data Views)」:同一個業務視圖被硬生生拆成兩套(實體/屬性在關聯式,關係在圖數據庫),應用層被迫承擔「整合數據語意」的責任,而這本來應該盡量由數據層去吸收。業界也常把「同一個應用同時使用多種數據庫」的策略稱為多語言持久化(Polyglot Persistence),其優點是各取所長,但代價是整合與一致性難度更高、維運與營運複雜度大幅提升。
回到多模型數據庫(Multi-model Database)的解決思路:核心重點是「統一」,而不是在同一條核心鏈路上不斷地「疊加」技術棧。它想回答的是:

以 ArangoDB 為例,其官方文件明確列出在單機(Single Server)情境下,多文件/多集合(Multi-document/Multi-collection)查詢可提供完整的 ACID 交易/事務保證。
最後虹科(HongKe)想要強調:「關聯式 + 圖數據庫」的混用架構並非原罪,但它有其嚴格的前提:業務邊界足夠清楚、系統規模可控、且團隊有足夠的人力與資源長期承擔數據同步與一致性的維護成本。如果您企業當前的主要矛盾已經是系統複雜度本身,那麼再試圖用「多加一個數據庫」去解決單點問題,很容易陷入「越疊加、越臃腫」的惡性循環。多模型數據庫的架構價值,恰恰在於透過「少一種拆分」,去大幅減少跨系統技術黏合所帶來的隱性隱藏成本。
眾多規則密集型企業於數位轉型時,常面臨業務規則與底層程式綁死、調校流程繁瑣、跨系統邏輯難統一等痛點。低程式碼可將判斷邏輯轉為可視化配置,縮短規則迭代週期,釐清業務與IT分工。Decisions平台整合低程式碼環境與規則引擎,獨立搭建共用決策層,支援拖拉式規則管理、跨系統串接調用,兼顧營運彈性與IT治理監管需求。
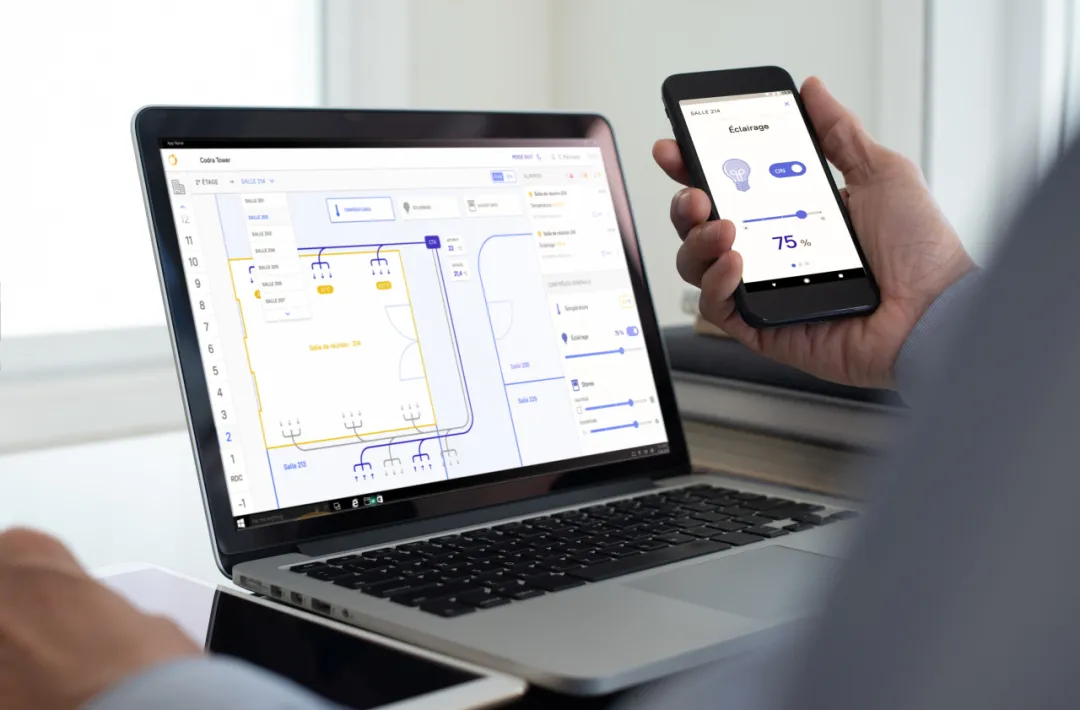
深入了解虹科 Panorama Suite 如何利用標準 REST Web Service (REST API) 實現雙向數據交換,打破工業現場數據孤島,將 SCADA 系統完美連接真實世界的天氣、能源與遙測大數據,全面加速企業 IT 與 OT 的深度融合。
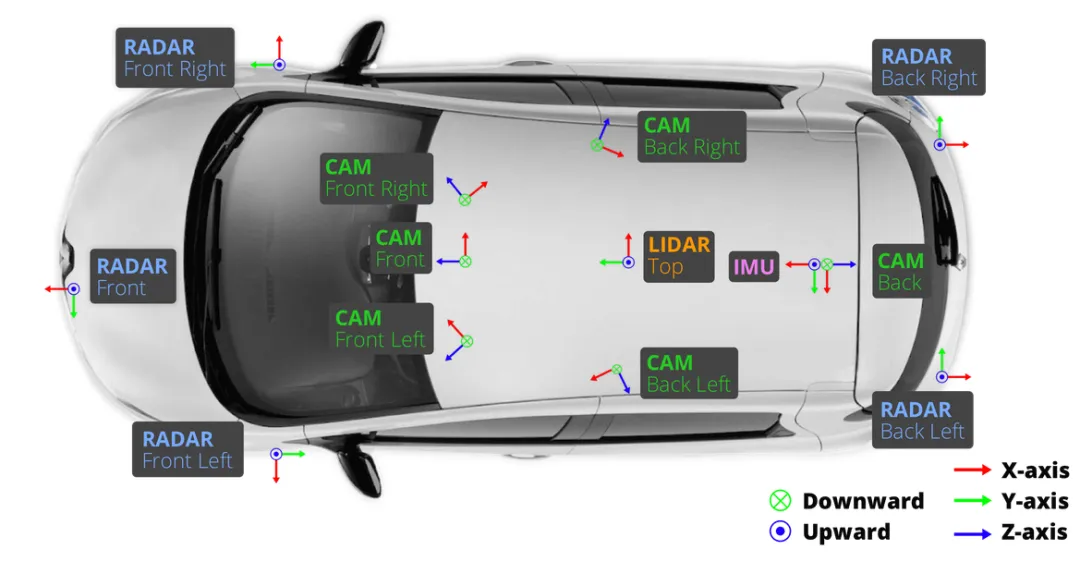
虹科推出SimData高保真虛擬數據集,依託aiSim仿真平台,完美兼容nuScenes格式。為自動駕駛感知算法、LiDAR、BEV模型提供高質量多模態訓練數據,有效解決極端場景(Edge Cases)採集難題。立即點擊了解構建流程與實測效果!
