

虹科乾貨
【虹科乾貨】AI 上線前先補洞:用「即時監控+權限治理」把資料外洩風險壓下來
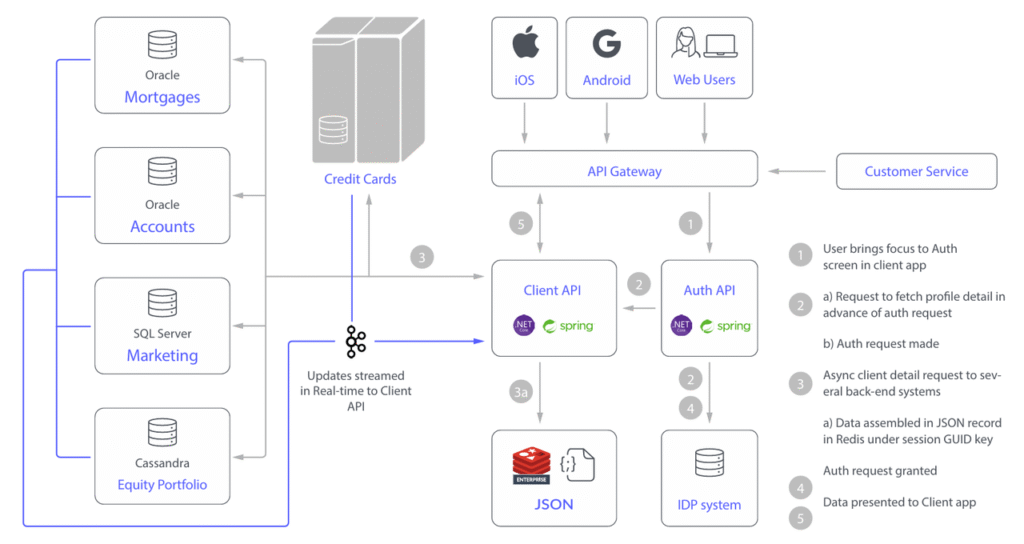
伴随生成式 AI、AI 代理在企业大规模落地,提示注入、过度代理、员工无意泄密等行为持续放大数据外泄与合规风险,企业亟需前置化安全防护方案。本文依托 Lepide 数据安全平台,围绕「部署前治理 + 运行中监控」搭建完整防护体系,通过实时敏感数据监测、细粒度权限管控、全链路审计与自动化应急处置能力,可联动 SIEM、SOAR 系统形成风险闭环。平台自动收敛过度权限,异常行为触发账号冻结、系统隔离等快速响应手段,解决 AI 权限泛滥、机密泄露难题,兼顾 GDPR 等法规合规需求,为企业 AI 落地筑牢数据安全防线。
